EdenFintech Scanner (Python)
Fundamental screener and scoring pipeline for a small US-listed equities watchlist, with a three-role LLM review stage behind a typed information barrier.

Stack: Python (stdlib-only core), LLM provider adapters isolated behind a transport abstraction, YAML config, pytest. Status: Active. The live surface is edenfintech.com. Source: private. Live: edenfintech.com
The story
The point of the scanner is to take a universe of US-listed equities, run a deterministic fundamental screen over them (solvency, dilution, revenue growth, ROIC, valuation), and produce a ranked output with a confidence band, something a person can read weekly and act on without scrolling through noise. The public version of the output is eden’s “insider cluster buy” weekly watchlist, but the pipeline underneath is broader than that.
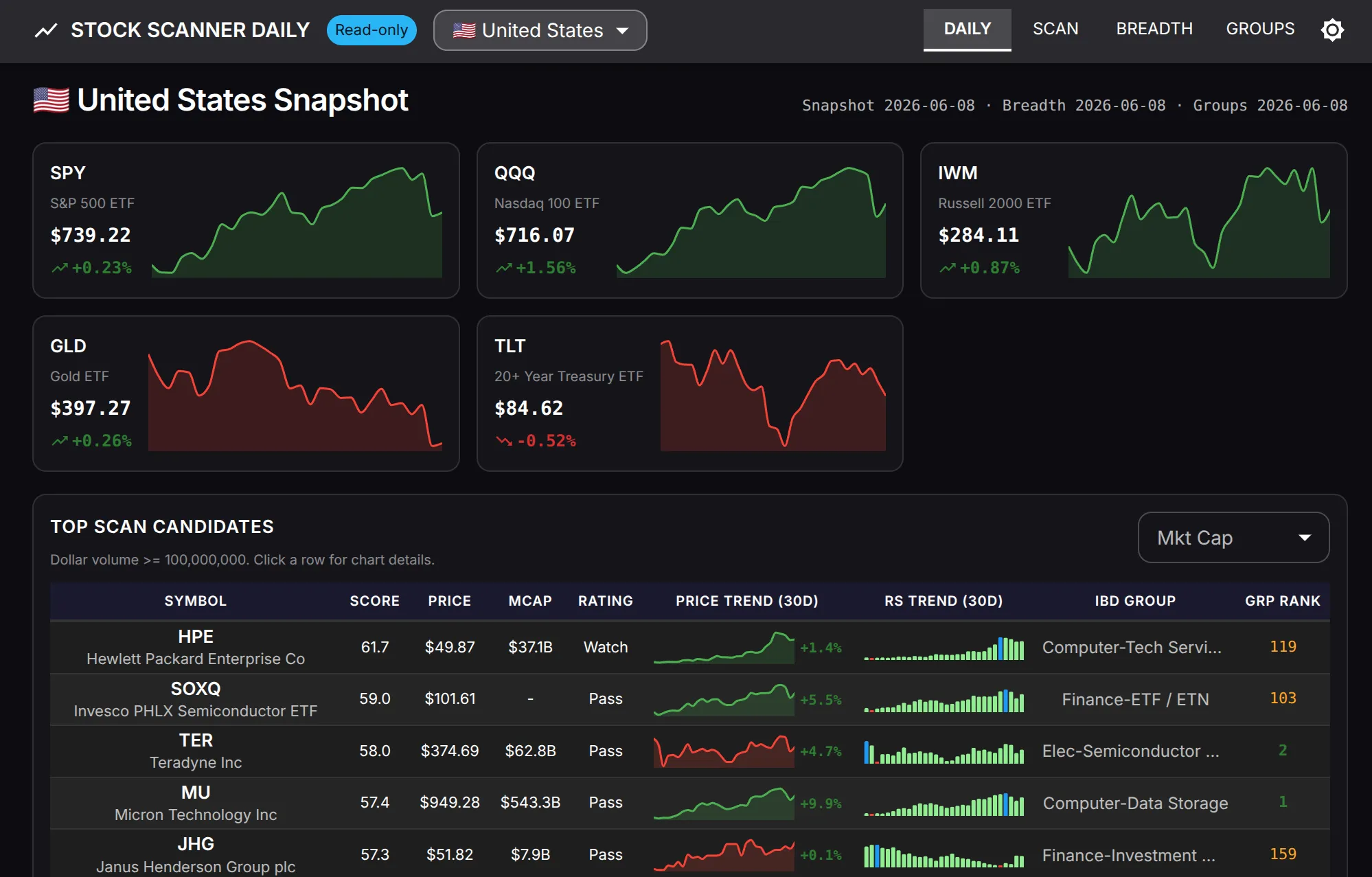
The parts I spent most of the time on are the ones that aren’t the scoring. There’s a contract-governed set of screening checks that’s regression-tested against fixtures. There’s a strategy-rules document, assets/methodology/strategy-rules.md, that is the single source of truth, if a helper disagrees with it, the methodology wins, not the helper. LLM calls sit behind an adapter layer exposing a Callable[[dict], dict] transport, so the core pipeline runs without any LLM SDK imported. The requirements.txt is a one-line comment saying so.
The agent graph is where the work compounds. An analyst role produces a narrative read over each candidate. A validator role checks specific claims. An epistemic reviewer writes a second opinion, but the data it receives is filtered by EpistemicReviewInput, a frozen dataclass that excludes scores, probabilities, valuations, and numeric targets. That isn’t a prompt instruction; it’s a type-level guarantee. The idea is that the reviewer’s job is to attack the thesis on its own terms, not mark the scorecard.
On top of that there’s a probability-anchoring detector that flags when the LLM is drifting toward round or prior-week numbers, a bias-check stage, and a three-agent unanimous exception panel that triggers on disagreements between the deterministic screen and the scored view. Every LLM call is logged with content-hash dedup, so a run is reproducible after the fact.
The pipeline has been used in anger, not just built. There are 22 numbered batch-* run directories in the repo, and 9 hydrated sector-knowledge files that accumulate over runs. The public EdenFintech site is the thin interface on top.
Architecture in one breath
main → fetch + snapshot + hash → deterministic screens (contract-tested) → scoring → agent graph (analyst → validator → epistemic reviewer, behind typed contracts) → content-hashed LLM log → JSON source-of-truth output → rendered markdown views.
Proof points
- ~12,000 LOC Python, stdlib-only in the core pipeline.
- 141 commits; active development.
- Three LLM roles, typed information barrier between analyst-output and reviewer-input.
- 22 numbered
batch-*run directories (real usage, not lab-only). - 9 hydrated sector-knowledge files built up over runs.
- CI mirrors the full local safety-check set.
What this proves
- AI / Agentic Systems, the typed information barrier, probability-anchoring detector, evidence-quality scorer, and per-call logging. LLM discipline at the code level rather than the prompt level.
- Quant Engineering, deterministic screening and scoring math (CAGR, floor price, decision score, confidence bands); contract-tested regressions.
- Python Services & Data Pipelines, stdlib-only core, transport injection, TTL cache with crash-safe meta-first writes, raw-bundle fingerprint continuity across runs.
